
Seu PC Virou um Cérebro Autônomo? Descubra o Hermes Agent e a Revolução da IA Local com NVIDIA!
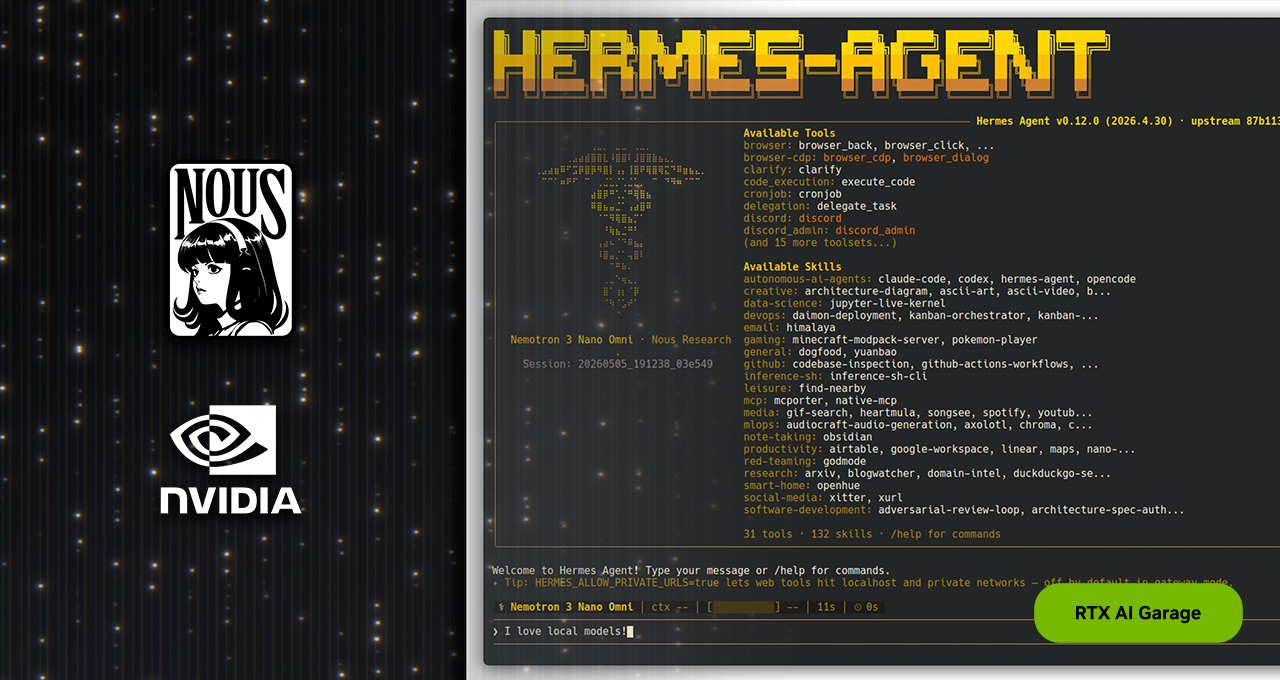
Olá, pessoal! Aqui é o Lucas Tech, e hoje a gente vai mergulhar em um assunto que está borbulhando no mundo da tecnologia e que promete mudar a forma como interagimos com a inteligência artificial: a IA Agente! Sabe, não estamos mais falando só de chatbots que respondem perguntas. A parada agora é a IA que age, que resolve problemas, que faz o trabalho por você! E nesse cenário, um nome está brilhando mais que estrela cadente: o Hermes Agent. Ele não só conquistou a comunidade open source rapidinho, com mais de 140 mil estrelas no GitHub em menos de três meses, como já é o agente mais usado do mundo, segundo o OpenRouter! Prepara o coração, porque a autonomia tá batendo na porta do seu PC!
O Hermes é uma criação genial da Nous Research, e o que mais impressiona nele é a forma como ele foi pensado para ser confiável e se aprimorar sozinho. Pensa só: essas são duas características que sempre foram um desafio enorme para os agentes de IA. Ele é super flexível, funcionando com qualquer provedor ou modelo de IA, e foi otimizado para rodar localmente, no seu próprio computador, 24 horas por dia. É por isso que PCs com NVIDIA RTX, estações de trabalho NVIDIA RTX PRO e até o super NVIDIA DGX Spark são o palco perfeito para o Hermes brilhar em velocidade máxima!
E para o Hermes não faltar cérebro, a Alibaba trouxe uma novidade incrível: a série Qwen 3.6 de modelos de linguagem (LLMs) de código aberto e alta performance. Eles são a dupla perfeita para rodar agentes locais como o Hermes. O mais legal é que os modelos Qwen 3.6 de 27B e 35B parâmetros estão superando versões anteriores que eram bem maiores (120B e 400B parâmetros!). Isso significa mais inteligência e menos "peso", rodando lisinho nas GPUs NVIDIA RTX e no DGX Spark para acelerar ainda mais essa IA superagente.
Hermes: Acelerando a IA Agente no Seu PC!
Assim como outros agentes por aí, o Hermes se conecta com seus apps de mensagens, acessa arquivos e programas no seu computador e pode trabalhar sem parar, 24 horas por dia, 7 dias por semana. Mas ele tem uns truques na manga que o fazem se destacar da multidão. Olha só esses quatro pontos que o deixam à frente:
Habilidades que Evoluem Sozinhas
Imagina uma IA que aprende com os próprios erros e sucessos? O Hermes faz exatamente isso! Ele escreve e refina as próprias habilidades. Cada vez que ele pega uma tarefa difícil ou recebe uma dica sua, ele salva esse aprendizado como uma nova habilidade. Ou seja, ele fica mais inteligente e eficiente a cada interação, se adaptando com o tempo!
Sub-Agentes Organizados e Focados
Sabe quando você tem um projeto grande e divide em várias partes menores? O Hermes faz o mesmo! Ele cria "sub-agentes" que são como pequenos trabalhadores independentes, cada um focado em uma parte específica da tarefa. Eles têm um contexto bem definido e as ferramentas certas para aquela sub-tarefa. Isso mantém tudo organizado, evita que o agente "se perca" e permite que o Hermes funcione com "janelas de contexto" menores, o que é perfeito para rodar esses modelos no seu PC.
Confiabilidade de Berço
A equipe da Nous Research não brinca em serviço! Eles testam cada habilidade, ferramenta e plug-in do Hermes exaustivamente para garantir que ele seja superconfiável. O resultado? O Hermes funciona que é uma beleza, mesmo com modelos locais mais parrudos (tipo os de 30 bilhões de parâmetros), sem aquela dor de cabeça de ficar debugando e corrigindo erros o tempo todo, algo comum em outros frameworks de agentes.
Mesmo Modelo, Resultados Superiores
Já viu testes onde o Hermes, usando o MESMO modelo de IA que outros frameworks, entrega resultados melhores? A diferença está na estrutura! O Hermes não é só uma "camada fininha" por cima do modelo; ele é uma camada de orquestração ativa, que permite que os agentes funcionem de forma persistente no seu dispositivo, em vez de executar uma tarefa por vez. Isso se traduz em mais eficiência e inteligência contínua!
É importante lembrar que tanto o Hermes quanto os LLMs que ele usa foram feitos para rodar localmente. Isso significa que a qualidade do seu hardware faz TODA a diferença na sua experiência! E é aí que as GPUs NVIDIA RTX entram com tudo, pois elas foram construídas exatamente para esse tipo de tarefa pesada.
Qwen 3.6: Inteligência de Data Center, mas no Seu PC!
A nova geração de modelos Qwen 3.6, que veio para turbinar a já excelente série Qwen 3.5, é um avanço gigantesco para os agentes de IA locais. Pensa só: o modelo Qwen 3.6 de 35B parâmetros precisa de só uns 20GB de memória para funcionar, mas consegue ser MAIS potente que modelos de 120 bilhões de parâmetros que exigem uns 70GB ou mais! É economia de recursos com performance de gente grande.
E não para por aí! O Qwen 3.6 27B é um modelo compacto, mas denso, com muitos parâmetros ativos que garantem uma precisão impressionante, igualando a de modelos gigantes de 400 bilhões de parâmetros (como o Qwen 3.5 397B), mas sendo 16 vezes MENOR! Rodar esses modelos em GPUs RTX de ponta é garantir a potência necessária para uma experiência ultra-rápida. Em resumo: esses Qwen 3.6 são perfeitos para agentes locais como o Hermes, e as GPUs NVIDIA (incluindo o DGX Spark) são o jeito mais rápido de fazê-los voar. Com os NVIDIA Tensor Cores, a inferência de IA é acelerada, entregando mais desempenho e menos atraso – o que significa que o Hermes pode resolver uma tarefa complexa ou aprimorar uma habilidade em segundos, não em minutos!
DGX Spark: Seu Computador Pessoal para IA 24/7!
Agentes como o Hermes são feitos para rodar sem parar: respondem a pedidos, planejam tarefas complexas, executam autonomamente e ainda se aprimoram! Para isso, o NVIDIA DGX Spark é o parceiro ideal. Pense nele como uma máquina compacta, super eficiente e autônoma, feita sob medida para fluxos de trabalho de agentes que operam o dia todo, sem folga.
Com impressionantes 128GB de memória unificada e 1 petaflop de performance em IA, o NVIDIA DGX Spark pode rodar modelos complexos (aqueles de mistura de especialistas com 120 bilhões de parâmetros) o dia inteiro sem suar. E com o novo modelo Qwen 3.6 de 35B parâmetros, você tem inteligência equivalente num pacote bem mais leve, rodando ainda mais rápido e te dando liberdade para executar várias tarefas ao mesmo tempo!
Para tirar o máximo de performance e facilitar sua vida, não deixe de conferir o playbook do Hermes DGX Spark. E se você é como eu e adora colocar a mão na massa, corre para se inscrever nas próximas sessões práticas da série "Faça Você Mesmo" da NVIDIA. Lá você vai aprender a construir agentes de IA autônomos com NemoClaw e OpenShell! Imperdível!
O NVIDIA DGX Spark já está disponível para pedidos com os parceiros da NVIDIA – dá uma olhada no marketplace se você ficou curioso!
Como Começar com o Hermes no Hardware NVIDIA? Simples!
Rodar o Hermes localmente no seu hardware NVIDIA é mais fácil do que você imagina. Vem ver!
Para começar, o primeiro passo é ir lá no repositório do Hermes no GitHub. Depois, é só escolher seu modelo local preferido e o runtime. Você pode rodar o Hermes junto com o Qwen 3.6 usando ferramentas como llama.cpp, LM Studio ou Ollama. O Hermes Agent já vem com suporte nativo para LM Studio e Ollama, o que torna a vida de quem quer um agente local super simples e plug-and-play!
Seja você um entusiasta de IA que adora explorar as fronteiras dos agentes pessoais ou um desenvolvedor criando ferramentas locais para seu trabalho, o Hermes rodando em hardware NVIDIA oferece uma base poderosa, única e super confiável para tudo isso.
E fiquem ligados para mais novidades do RTX AI Garage sobre os modelos e agentes abertos mais recentes, todos otimizados para o hardware NVIDIA RTX!
#FicaADica: As Últimas do RTX AI Garage que Você NÃO Pode Perder!
✨ As GPUs NVIDIA RTX PRO estão entregando uma geração de tokens até 3x mais rápida ao rodar os modelos Qwen 3.6 com llama.cpp. Isso significa aquela responsividade em tempo real que a IA local tanto precisa, permitindo que seus agentes resolvam tarefas complexas e aprimorem suas habilidades para um fluxo de trabalho sem interrupções.
🚀 Os modelos Gemma 4 de 26B e 31B do Google agora estão disponíveis como checkpoints NVFP4, o que significa ainda mais performance nas GPUs NVIDIA Blackwell. Combine esses checkpoints NVFP4 com os novos rascunhadores de Predição Multitoken do Google para ter uma inferência até 3x mais rápida com a mesma qualidade de saída! Ou seja, raciocínio de ponta rodando localmente nas suas GPUs NVIDIA.
🍃 O Mistral Medium versão 3.5, lançado em abril, trouxe atualizações de compatibilidade com llama.cpp e Ollama, permitindo que a galera rode ele nos sistemas NVIDIA RTX PRO e DGX Spark sem problemas.
🦞 A NVIDIA lançou o NVIDIA NemoClaw, um stack de código aberto que otimiza as experiências do OpenClaw em dispositivos NVIDIA, aumentando a segurança e dando suporte a modelos locais. E a boa notícia é que o NemoClaw agora suporta o Subsistema Windows para Linux (WSL2), o que traz um baita suporte para entusiastas e desenvolvedores na plataforma da Microsoft. Que tal começar a usar o NemoClaw no DGX Spark com este guia passo a passo?
Quer ficar por dentro de tudo sobre IA no seu PC? Siga a NVIDIA AI PC no Facebook, Instagram, TikTok e X! E não esqueça de se inscrever na newsletter do RTX AI PC para não perder nada. Ah, e se curte workstation, acompanha a NVIDIA Workstation no LinkedIn e X também! Fica a dica 😉
Verifique o aviso referente às informações do produto de software.
Minha Visão
Caramba, pessoal! Como entusiasta de tecnologia, ver o Hermes Agent explodindo desse jeito e, principalmente, sendo otimizado para rodar localmente nas GPUs NVIDIA, me deixa realmente empolgado. Isso não é só mais uma ferramenta; é um passo gigantesco para a democratização da inteligência artificial. Ter um agente capaz de aprender sozinho, que é super confiável e ainda por cima roda no meu PC com uma performance absurda, é um game-changer. Imagine as possibilidades: assistentes pessoais ultra-eficientes, ferramentas de trabalho que se adaptam perfeitamente às suas necessidades, automações que parecem mágica… Tudo isso com a privacidade e o controle que só o processamento local pode oferecer. É o futuro batendo na porta, e ele parece mais inteligente e acessível do que nunca!
E aí, o que vocês acham dessa revolução dos agentes de IA? Será que o Hermes Agent é o primeiro de muitos a transformar nosso dia a dia, trazendo inteligência de ponta para a ponta dos nossos dedos? Deixem seus comentários e vamos continuar essa conversa!
Referência: Matéria Original
Posts relacionados:

THINK: The user wants me to rewrite a long, technical English title into a short, curious Portuguese title suitable for Google Discover. I need to focus on the "autonomous machine learning research loop" and "hyperparameter discovery" aspects, making it sound intriguing without being overly complex. I must only return the final title.
Analyze the original title:
- "How to Build an Autonomous Machine Learning Research Loop in Google Colab Using Andrej Karpathy’s AutoResearch Framework for Hyperparameter Discovery and Experiment Tracking"
- Core idea 1: Autonomous ML Research Loop
- Core idea 2: Hyperparameter Discovery / Experiment Tracking
- Tool: Google Colab
- Framework: Andrej Karpathy’s AutoResearch Framework (this is too specific/long for Discover)
Identify key concepts for curiosity:
- "Autonomous" -> automatizado, sozinho, sem você
- "Research Loop" -> pesquisa, descoberta, otimização
- "Machine Learning" -> IA, aprendizado de máquina
- "Hyperparameter Discovery" -> melhores resultados, segredos, IA que se aprimora
- "Google Colab" -> fácil, acessível
Brainstorm short, curious Portuguese phrases:
- "Sua IA faz pesquisa sozinha?" (Too informal/simplistic)
- "Colab: sua IA descobre os segredos sozinha."
- "Máquina que aprende sozinha: o loop de pesquisa."
- "Automação ML: deixe a IA otimizar tudo."
- "Descoberta de hiperparâmetros: a IA faz por você."
- "Colab: IA autônoma em pesquisa."
- "Sua IA pesquisa e se aprimora sozinha."
- "Colab: Sua IA pesquisa e se aprimora SOZINHA?"
Refine for Discover style (short, curious, engaging):
- Needs to hint at the "loop" and "discovery" without being explicit about the technical terms.
- "Autonomous" is strong. "Máquina que aprende sozinha" is good.
- "Colab" is a recognizable platform.
- Focus on the benefit: better results, faster discovery, less manual work.
Draft options and evaluate:
- Option 1: "Sua IA pesquisa e se aprimora sozinha no Colab?" (Good, curious, short, uses "sozinha" for autonomous and "aprimora" for hyperparameter discovery/experiment tracking implicitly).
- Option 2: "Colab: Deixe sua IA descobrir os melhores parâmetros." (A bit less about the "loop" and "research," more specific to parameters).
- Option 3: "Máquina que aprende sozinha: o segredo no Colab." (Intriguing, but "segredo" might be too vague).
- Option 4: "Crie uma IA que pesquisa sozinha no Google Colab." (Good, but "crie" might imply building the AI, not just the loop).
- Option 5: "Colab: Sua IA já otimiza os próprios resultados?" (Good, focuses on optimization and "próprios" implies autonomous).
Select the best fit: Option 1 or 5 are strong. Option 1 "Sua IA pesquisa e se aprimora sozinha no Colab?" directly addresses the "research loop" (pesquisa) and "hyperparameter discovery/experiment tracking" (aprimora), while keeping it curious and short. "Sozinha" captures "autonomous." It’s also a question, which is good for Discover engagement.
Let’s try to make it even more punchy, maybe less of a question. "Colab: Sua IA Otimiza Sozinha?" (Too short, loses "research") "Colab: A IA Que Pesquisa e Se Aprimora SOZINHA" (Strong, emphasizes "sozinha") "Descubra: Sua IA Pesquisa E Otimiza Sozinha?" (Adds "Descubra" for curiosity) "Colab: Sua IA já se aprimora sozinha?" (Good, concise, highlights the autonomous self-improvement)
Let’s go with a direct, intriguing question that hints at the core functionality. The "loop" implies continuous research and improvement.
"Sua IA Pesquisa e Otimiza SOZINHA no Colab?" This captures:
- "Pesquisa" (Research loop)
- "Otimiza" (Hyperparameter discovery, experiment tracking, improvement)
- "SOZINHA" (Autonomous)
- "Colab" (Platform)
- It’s a question, making it curious.
- It’s short.
I think "Sua IA Pesquisa e Otimiza SOZINHA no Colab?" is a very good fit. It’s direct, curious, and covers the main points succinctly.
Let’s try one more: "Colab: Sua IA Já Otimiza os Próprios Experimentos?" This is also good, "otimiza os próprios experimentos" maps well to the hyperparameter discovery and experiment tracking loop. "Próprios" implies autonomous.
I will go with something that highlights the "alone/autonomous" aspect clearly, and the "improvement" or "research" part.
"Colab: Sua IA pesquisa e se aprimora SOZINHA?" – This uses "pesquisa" (research) and "aprimora" (improves/optimizes) and "sozinha" (autonomous) and "Colab". It’s a question, short, and curious. This feels like a strong contender.Colab: Sua IA pesquisa e se aprimora SOZINHA?
 IA que Age Sozinha: Revolução nas Finanças.
IA que Age Sozinha: Revolução nas Finanças.
 RTX Liberta Gemma 4: IA Que Pensa Sozinha?
RTX Liberta Gemma 4: IA Que Pensa Sozinha?
 AutoKernel: A IA que Otimiza GPUs PyTorch Sozinha!
AutoKernel: A IA que Otimiza GPUs PyTorch Sozinha!