
A Meta Acaba de Revelar o Segredo para Salvar o Futuro da IA! Entenda o GCM!
Olá, pessoal! Aqui é o Lucas Tech, seu amigo entusiasta de tecnologia de 28 anos, e hoje a gente vai mergulhar em um assunto que não está nas manchetes das redes sociais, mas que é absolutamente crucial para o futuro da Inteligência Artificial que a gente tanto ama! Enquanto a galera da tecnologia pira nos novos modelos Llama e suas capacidades incríveis, rola uma batalha bem mais "barra pesada" e escondida lá nos porões dos data centers.
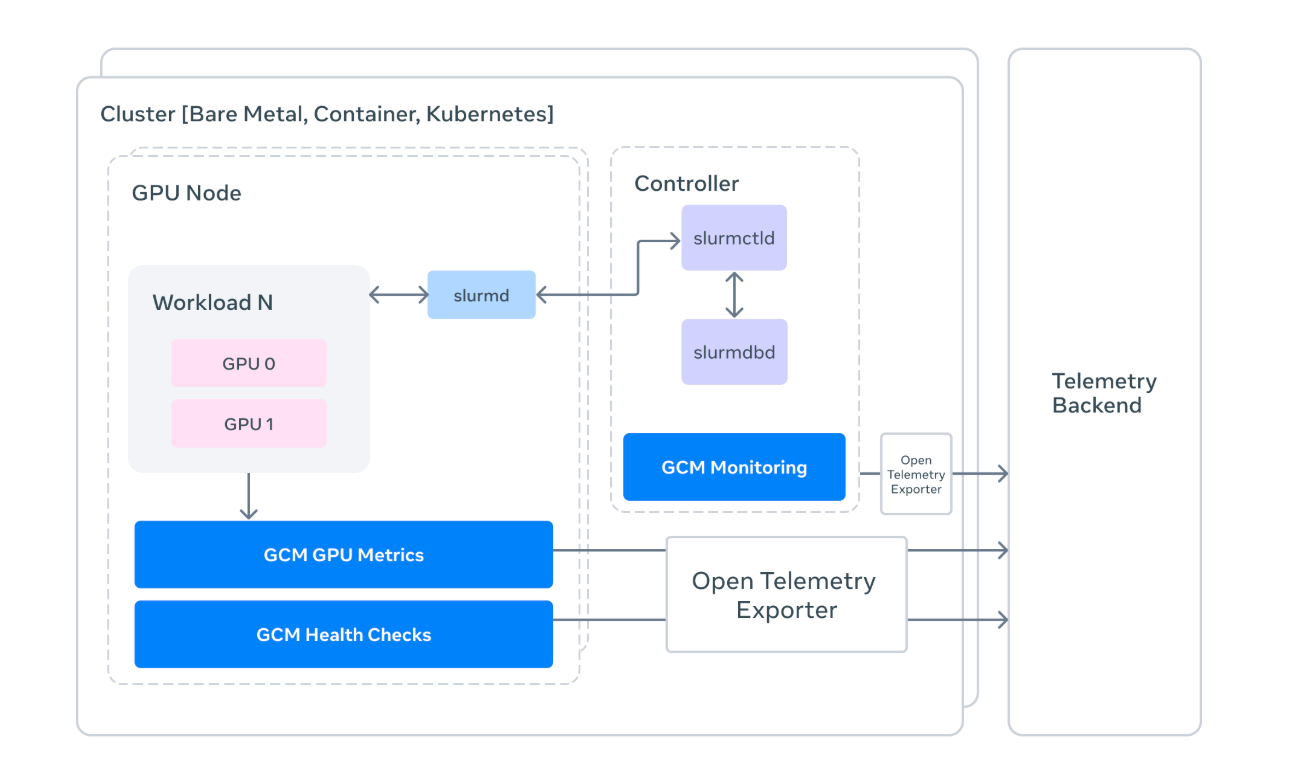
Pensa comigo: quando os modelos de IA escalam para trilhões de parâmetros, os clusters de computadores necessários para treiná-los viram máquinas gigantescas, supercomplexas e, ironicamente, mega frágeis! Qualquer probleminha ali pode sabotar tudo. E foi pensando nisso que a equipe de Meta AI Research soltou uma ferramenta que pode mudar o jogo: o GCM (GPU Cluster Monitoring). Ele é um kit de ferramentas especializado para resolver o que eles chamam de "assassino silencioso" do progresso da IA: a instabilidade do hardware em larga escala. Basicamente, o GCM é um manual de instruções de como conectar o hardware e o software de um jeito que funcione de verdade na Computação de Alto Desempenho (HPC).
O Problema Invisível: Quando o Básico Não Serve Mais
No mundo do desenvolvimento web tradicional, se um microsserviço dá uma engasgada, você corre para o seu dashboard, identifica o problema e escala horizontalmente. Simples, né? Mas no treinamento de IA, as regras são totalmente diferentes. Imagina um cluster com 4.096 placas de GPU. Se uma única GPU ali tiver uma "falha silenciosa" – tipo, ela está tecnicamente "ligada", mas o desempenho dela despencou – isso pode simplesmente "envenenar" os gradientes de todo o processo de treinamento. O que significa isso? Horas (e dinheiro!) de processamento jogados fora e um modelo de IA que não aprende direito.
As ferramentas de monitoramento padrão, muitas vezes, são muito superficiais para pegar esses detalhes mais finos. É aí que o GCM da Meta entra como uma ponte especializada, conectando a telemetria bruta do hardware das GPUs NVIDIA diretamente com a lógica de orquestração do cluster. Ele vê o que os outros não veem!
Como o GCM Salva o Dia? As Estratégias por Trás
A Meta não brincou em serviço. O GCM vem com algumas sacadas geniais para garantir que os clusters estejam sempre no seu melhor.
1. Monitorando no ‘Estilo Slurm’
Para os desenvolvedores, o Slurm é aquele gerenciador de carga de trabalho onipresente (e, às vezes, um pouco irritante, confesso!) que gerencia tarefas em clusters. O GCM se integra diretamente com o Slurm para oferecer um monitoramento supercontextualizado.
- Atribuição por Job ID: Em vez de ver um pico genérico de consumo de energia, o GCM permite que você atribua métricas a Job IDs específicos. Ou seja, você sabe exatamente qual trabalho (e qual pesquisador!) está usando quais recursos e como.
- Rastreamento de Estado: Ele puxa dados de comandos como
sacct,sinfoesqueuepara criar um mapa em tempo real da saúde do cluster. Se um nó está marcado comoDRAIN(drenagem, indicando um problema), o GCM ajuda a entender por que antes que isso estrague o fim de semana de um pesquisador que depende daquele nó!
2. A Tática do ‘Prolog’ e ‘Epilog’: Check-ups Essenciais
Uma das partes mais tecnicamente vitais do GCM são seus "Health Checks" (verificações de saúde). Em um ambiente HPC, o timing é tudo. O GCM usa duas janelas de tempo cruciais:
- Prolog: São scripts que rodam antes de um trabalho começar. O GCM verifica se a rede InfiniBand (aquelas conexões super rápidas entre as GPUs) está saudável e se as GPUs estão realmente acessíveis. Se um nó falhar neste pré-teste, o trabalho é desviado para outro lugar, economizando horas de tempo de computação "morto" e caríssimo.
- Epilog: Estes rodam depois que um trabalho termina. O GCM usa esta janela para fazer diagnósticos mais profundos, utilizando o NVIDIA DCGM (Data Center GPU Manager) para garantir que o hardware não foi danificado durante o "trabalho pesado" do treinamento. Pensa em um check-up pós-treino!
3. Telemetria e a Ponte OTLP: Vendo o Invisível
Para os devs e pesquisadores de IA que precisam justificar seus orçamentos de computação (sim, GPU custa caro!), o Processador de Telemetria do GCM é a estrela do show. Ele pega os dados brutos do cluster e os converte para formatos OpenTelemetry (OTLP).
Ao padronizar essa telemetria, o GCM permite que as equipes enviem dados específicos do hardware (como temperatura da GPU, erros de NVLink e eventos XID) para stacks de observabilidade modernas. Isso significa que você finalmente pode correlacionar uma queda no desempenho do treinamento com um evento específico de throttle (diminuição intencional de desempenho para evitar superaquecimento) no hardware. Em vez de dizer "o modelo está lento", você pode dizer "a GPU 3 no Nó 50 está superaquecendo, precisamos verificar!". Isso é game changer!
Por Baixo do Capô: A Magia da Engenharia
A implementação da Meta é uma verdadeira aula magna de engenharia prática. O repositório é majoritariamente Python (94%), o que o torna super fácil de estender para os devs de IA. Mas, para aquelas partes críticas de performance, a lógica é tratada em Go, garantindo velocidade e eficiência.
- Collectors: São componentes modulares que coletam telemetria de diversas fontes, como o
nvidia-smi(ferramenta da NVIDIA para monitorar GPUs) e a API do Slurm. - Sinks: Essa é a camada de "saída". O GCM suporta múltiplos sinks, incluindo
stdoutpara depuração local e OTLP para monitoramento de nível de produção. - DCGM & NVML: O GCM se beneficia da NVIDIA Management Library (NVML) para conversar diretamente com o hardware, ignorando abstrações de alto nível que poderiam esconder erros importantes.
Pontos Chave: O Que Você Precisa Guardar!
Resumindo, pessoal, o GCM da Meta é uma virada de jogo por várias razões:
- Ele resolve o problema das ‘falhas silenciosas’: Aquelas GPUs ‘zumbis’ que parecem online, mas estão sabotando o treinamento da IA com gradientes corrompidos.
- Integração profunda com Slurm: Diferente de outros monitores genéricos, o GCM foi feito sob medida para HPC. Ele ‘ancora’ as métricas de hardware aos IDs de trabalho do Slurm, permitindo que os engenheiros saibam exatamente qual modelo e usuário estão causando problemas.
- Check-ups automatizados com ‘Prolog’ e ‘Epilog’: Uma estratégia proativa! Ele verifica a saúde do hardware antes de começar um trabalho e faz um diagnóstico aprofundado depois que ele termina, tudo para evitar o desperdício de tempo de computação caríssimo.
- Telemetria padronizada via OTLP: Ele transforma aqueles dados complexos do hardware (temperatura, erros de NVLink) em um formato universal (OpenTelemetry), facilitando a integração com ferramentas modernas de observabilidade como Prometheus e Grafana.
- Design modular e acessível: Embora o núcleo seja em Python (fácil de usar!), as partes críticas rodam em Go (velocidade!). Sua arquitetura de ‘Coletor e Sink’ permite que devs pluguem facilmente novas fontes de dados ou exportem métricas para qualquer sistema.
Minha Visão
Pra mim, Lucas Tech, essa notícia não é só mais uma atualização técnica; é um passo gigantesco para a democratização e a estabilidade da pesquisa em IA. Pense bem: a Meta está abrindo o jogo e compartilhando uma ferramenta que resolve um problema que custa milhões em recursos e tempo de pesquisa. Isso significa que mais empresas e equipes de pesquisa, talvez até com orçamentos menores, poderão treinar modelos de IA gigantes de forma mais eficiente e confiável. É a base invisível que vai permitir que a próxima geração de IAs seja ainda mais robusta e menos propensa a falhas "misteriosas". É um game changer que acelera a inovação em IA para todo mundo!
E você, o que pensa sobre essa nova ferramenta? Já imaginava que esses problemas existiam nos bastidores da IA? Deixa seu comentário!
Referência: Matéria Original
Posts relacionados:
 Taalas: 17.000 tokens/seg! O segredo? Chips de IA, não GPUs.
Taalas: 17.000 tokens/seg! O segredo? Chips de IA, não GPUs.
 Suas Ray-Bans Meta estão recebendo várias atualizações gratuitas para gravação de vídeo – assim como os modelos da Oakley.
Suas Ray-Bans Meta estão recebendo várias atualizações gratuitas para gravação de vídeo – assim como os modelos da Oakley.
 Como a forma como você carrega seu tablet pode prejudicá-lo – 3 erros a evitar (e a maneira correta)
Como a forma como você carrega seu tablet pode prejudicá-lo – 3 erros a evitar (e a maneira correta)
 Como a forma como você carrega seu tablet pode danificá-lo silenciosamente – 3 erros a evitar (e a maneira correta)
Como a forma como você carrega seu tablet pode danificá-lo silenciosamente – 3 erros a evitar (e a maneira correta)